Mastodon, le réseau social libre qui est en train de bousculer twitter
Une alternative à Twitter, libre et décentralisée, est en train de connaître un succès aussi spontané que jubilatoire…

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code
La catégorie « Enjeux du numérique » c’est un coin de sensibilisation sur le numérique, ses dérives, et ses bonnes pratiques.

Une alternative à Twitter, libre et décentralisée, est en train de connaître un succès aussi spontané que jubilatoire…

De simples citoyens ont-ils un rôle à jouer dans les sciences, où ils sont pour l’instant contingentés au mieux à des fonctions subalternes ?

Nous avons la chance d’être autorisés à traduire et publier un long article qui nous tient à cœur : les idées et analyses qu’il développe justifient largement les actions que nous menons avec vous et pour le plus grand nombre.
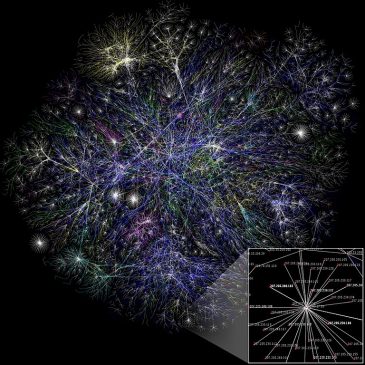
Non, nous n’allons vous parler de fibres (quoique). C’est du transit d’Internet que nous allons parler. Ou plutôt, nous allons laisser Stéphane Bortzmeyer en parler.

Notre Framatophe a préparé un manuel de l’Internet à l’intention des Dupuis-Morizeau, cette sympathique famille de français moyens que nous chahutons chouchoutons à longueur d’année. Ce n’est surtout pas un livre « pour les nuls » (ça va couper, chérie) mais un … Lire la suite

La création d’un site web depuis votre compte Framagit est beaucoup plus souple, et c’est une belle victoire pour le libre !

À l’occasion du 28e anniversaire du World Wide Web, son inventeur Tim Berners-Lee a publié une lettre ouverte dans laquelle il expose ses inquiétudes concernant l’évolution du Web, notamment la perte de contrôle sur les données personnelles, la désinformation en … Lire la suite

En quelques années à peine s’est élevée dans une grande partie de la population la conscience diffuse des menaces que font peser la surveillance et le pistage sur la vie privée.