Nous devons nous passer de Chrome
Chrome, de navigateur internet novateur et ouvert, est devenu au fil des années un rouage essentiel de la domination d’Internet par Google.

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code
La catégorie Google Apple Facebook Amazon Microsoft évoque la bataille sans merci que se livrent ces géants sur tous les fronts… Et leur avidité pour nos données et notre attention. Et le logiciel libre dans tout ça ?

Chrome, de navigateur internet novateur et ouvert, est devenu au fil des années un rouage essentiel de la domination d’Internet par Google.
Alors que se répandent les enceintes connectées (comme le Google Home ou l’Amazon Echo), fleurissent aussi des projets pour les empêcher de vous écouter en permanence (ce qui est nécessaire à leur fonctionnement normal, rappelons-le). Cela peut faire sourire car … Lire la suite

Ces dernières semaines nous avons publié par chapitres successifs notre traduction de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Vous trouverez ci-dessous en un seul … Lire la suite
Voici déjà la traduction du septième chapitre et de la brève conclusion de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, … Lire la suite
Voici déjà la traduction du sixième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà … Lire la suite
Voici déjà la traduction du cinquième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà … Lire la suite
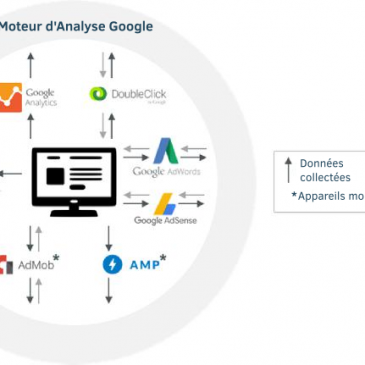
Voici déjà la traduction du quatrième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà … Lire la suite

Nous sommes ravis et honorés d’accueillir Stéphane Bortzmeyer qui allie une compétence de haut niveau sur des questions assez techniques et une intéressante capacité à rendre assez claires des choses complexes. Nous le remercions de nous expliquer dans cet article … Lire la suite