Les nouveaux Léviathans IV. La surveillance qui vient
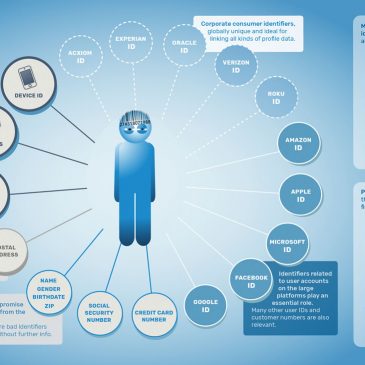
Dans ce quatrième numéro de la série Nouveaux Léviathans, nous allons voir dans quelle mesure le modèle économique a développé son besoin vital de la captation des données relatives à la vie privée. De fait, nous vivons dans le même … Lire la suite