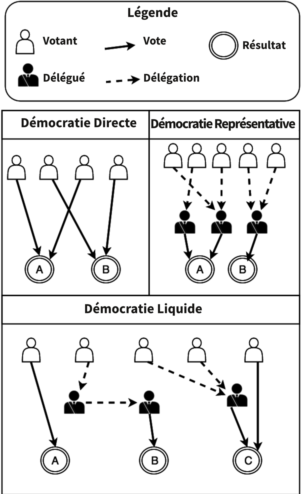
Framacalc Reloaded : la force de vos feuilles de calculs se réveille !
Notre tableur en ligne, basé sur le logiciel libre Ethercalc, est déjà largement utilisé… au point d’être parfois victime de son succès ! C’est bien connu : plus un logiciel (ou un service) a d’utilisateurs, plus ils souhaitent, suggèrent et apportent des … Lire la suite