La première démonstration de MyPads est disponible !
Framapad — un de nos services Libre, Éthique, Décentralisé et Solidaire les plus utilisés — permet de rédiger des documents collaborativement et en temps réel.

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code
La catégorie « Outils émancipateurs » mentionne différents outils numériques qui permettent aux humain⋅es de reprendre le contrôle sur leurs vies numériques.
Framapad — un de nos services Libre, Éthique, Décentralisé et Solidaire les plus utilisés — permet de rédiger des documents collaborativement et en temps réel.

Ce qui a été fait Un certain nombre de tâches ont pu être travaillées en semaine 23, et notamment : un premier jet du module de partage d’administration et d’invitation d’utilisateurs (en mode visibilité restreinte) pour les groupes pour le moment, … Lire la suite
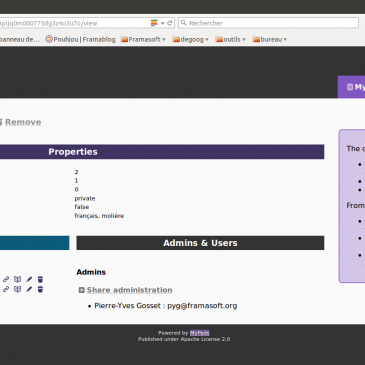
Travaux effectués La semaine dernière a été mise à profit pour : la réalisation de la page de détails des groupes, laquelle comprend : toutes les propriétés du groupes affichées ; la liste des administrateurs et utilisateurs du groupe ; la liste des pads … Lire la suite

Des ordis moins énergivores (mais aussi efficaces) pour les institutions françaises. Libres. assemblés en France ? C’est le pari osé d’une association de Nevers, qui a besoin de sous pour démarrer. Nous avons voulu en savoir plus avant, peut-être, de mettre … Lire la suite
Tâches réalisées Le prestataire a été à l’arrêt pour raison médicale la semaine 20 ainsi qu’une partie de la semaine 21. Les avancées n’ont donc couru que sur quelques journées et se sont focalisées sur la page de liste des … Lire la suite

…nous dit Richard Stallman. Le logiciel a ses licences libres, la culture et la création artistique ont aussi leurs licences libres. Mais depuis quelques années les créations physiques libres se multiplient, ce qui rend urgent de poser les questions des … Lire la suite
Si vous utilisez un traitement de texte avec des élèves, vous avez sûrement déjà entendu cette phrase « Il n’y a pas d’erreurs car ce n’est pas souligné. » En effet, trop souvent, seul le correcteur orthographique est utilisé. Et comme son … Lire la suite
Travaux effectués Comme prévu, le travail a été poursuivi du côté des groupes de pads. Plus en détail : la modification des groupes existants, avec la conservation du mot de passe en mode privé (pas besoin de le saisir à nouveau) ; … Lire la suite