Emancip’Asso – L’éthique, jusqu’au bout du numérique !
🦆 VS 😈 : Reprenons du terrain aux géants du web !
Grâce à vos dons (défiscalisables à 66 %), l’association Framasoft agit pour faire avancer le web éthique et convivial. Retrouvez un résumé de nos avancées en 2023 sur le site Soutenir Framasoft.
➡️ Lire la série d’articles de cette campagne (nov. – déc. 2023)

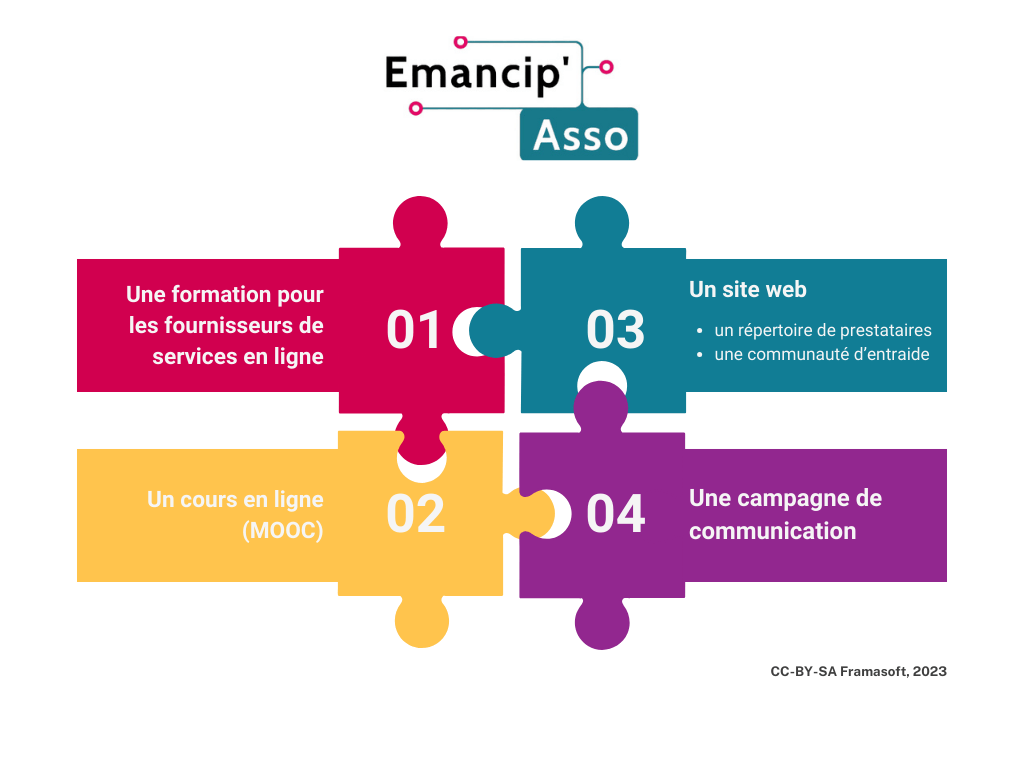
Emancip’Asso, un projet en 4 actions
Conçu en 2021 en partenariat avec Animafac, copiloté par un grand nombre d’organisations impliquées dans les secteurs de l’éducation populaire, de l’associatif et du numérique et intégré dans notre feuille de route « Collectivisons Internet / Convivialisons Internet », le projet Emancip’Asso a pour objectif principal de mettre en lien fournisseurs de services numériques éthiques et associations ayant besoin d’être accompagnées dans leur démarche de transition numérique émancipatrice.
Pour atteindre son objectif, le projet prévoit de se décliner en 4 actions :
- une formation pour les fournisseurs de services en ligne éthiques ;
- un cours en ligne, déclinaison en numérique de la formation ;
- un site web recensant des prestataires spécialistes de l’accompagnement à la transition numérique des associations et proposant un espace d’entraide et de mutualisation des besoins entre associations ;
- une campagne de communication de grande ampleur pour inciter les associations à prendre conscience de l’incohérence qu’il y a à vouloir changer le monde en utilisant les outils du capitalisme.
Cette année aura été bien remplie : les 3 premières actions détaillées ci-dessus sont désormais réalisées ! On vous détaille tout ça dans la suite de cet article.
Former les fournisseurs de services numériques éthiques à l’accompagnement des associations
Nous faisons un constat : les fournisseurs de services numériques éthiques sont peu nombreux à proposer des solutions prenant réellement en compte les besoins des associations, notamment l’accompagnement nécessaire pour mener à bien une démarche de transition vers des outils numériques libres. La première étape du projet Emancip’Asso se donne ainsi pour objectif d’accompagner la montée en compétences de ces acteurices à travers deux dispositifs : une formation et un cours en ligne (MOOC).
Une formation très appréciée en janvier 2023
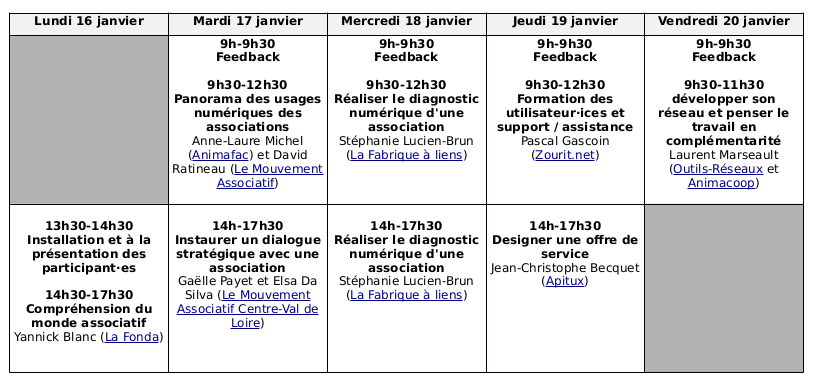
20 personnes se sont donc retrouvées à Paris du 16 au 20 janvier dans les locaux de la FPH (Fondation Charles Léopold Mayer pour le progrès de l’Homme) pour participer à la formation « Développer une offre de services pour accompagner les associations dans leur transition numérique éthique ». Si le programme initial de la formation a dû être légèrement modifié, le jeudi 19 janvier étant une journée de mobilisation contre la réforme des retraites, l’ensemble des interventions a quand même pu avoir lieu au cours de la semaine.

Remercions encore une fois les 9 personnes qui ont accepté d’intervenir pendant cette session de formation pour partager leurs domaines d’expertise et échanger avec les participant⋅es. Leurs interventions ont été très appréciées (voir ci-dessous) et se sont révélées précieuses, constituant une base solide de savoirs et de ressources pour la production du MOOC.
Remercions aussi les 20 personnes qui ont suivi avec assiduité les 7 séquences de cette formation et ont pris part aux nombreux échanges informels qui s’y sont tenus. Notre objectif de former en priorité les hébergeurs alternatifs membres du Collectif des Hébergeurs Alternatifs Transparents Ouverts Neutres et Solidaires (CHATONS) est atteint puisque 70% des participant⋅es sont actif⋅ves au sein d’une organisation membre du collectif CHATONS (14 personnes), représentant au total 11 structures membres du collectif CHATONS (Alolise, Assodev-Marsnet, le Cloud Girofle, la Contre-Voie, Deuxfleurs, Immae.eu, Libretic, Nebulae, Pâquerette, Picasoft et Sleto). Sur les 6 autres participant⋅es, l’un a vu son organisation (FuturEtic) intégrer le collectif CHATONS en juin 2023 et un autre (Krashboyz Bordel Klub) est actuellement candidat pour le rejoindre.
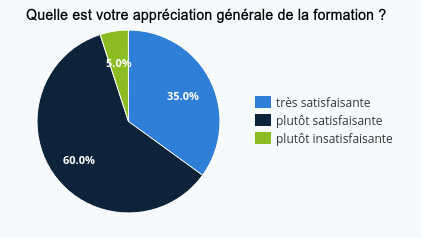
Le questionnaire de satisfaction que nous avons transmis aux participant⋅es met en évidence le fait que dans sa globalité, cette semaine a été bénéfique pour toustes. Ainsi, 35% des apprenant⋅es ont trouvé la formation très satisfaisante, 60% plutôt satisfaisante et un⋅e seul⋅e participant⋅e a considéré que cette formation était plutôt insatisfaisante.
Les séquences pédagogiques qui ont le plus été appréciées sont les suivantes :
- réaliser le diagnostic numérique d’une association
- développer son réseau et penser le travail en complémentarité
- communication et design d’une offre de service
- formation des utilisateur⋅ices et support / assistance
- panorama des usages numériques des associations
- compréhension du monde associatif
- instaurer un dialogue stratégique avec l’association
(taux de satisfaction calculé sur la base de 5 critères : qualité du contenu théorique, qualité du contenu pratique, qualité de l’approche pédagogique, qualité des outils d’animation et capacité d’écoute/disponibilité)
Nous avons aussi demandé aux participant⋅es leur degré de satisfaction sur les autres aspects de la formation. Et comme nous l’indique le schéma ci-dessous, la satisfaction est globale, sauf quelques rares exceptions.
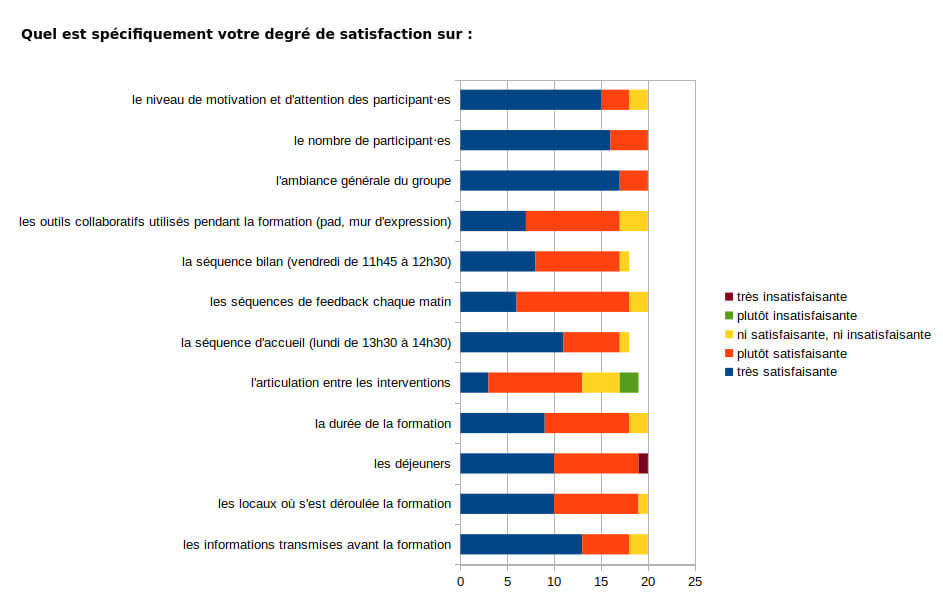
Nous gardons cependant en tête que certains aspects pourraient être améliorés :
- favoriser des modalités de transmission des savoirs moins descendantes,
- prévoir davantage de travaux pratiques et d’échanges de pratiques,
- améliorer la cohérence entre les interventions,
- utiliser des locaux plus adaptés.
Et nous ferons de notre mieux si nous venions à envisager de reconduire cette formation à l’avenir. Mais pour le moment, nous n’avons pas les financements pour cela.
Un MOOC très complet en décembre 2023
Il nous a fallu quasiment une année pour transformer la session de formation en MOOC, mais ça y est, le cours en ligne « Développer une offre de services pour accompagner les associations dans leur transition numérique éthique » est désormais accessible sur la plateforme MOOC CHATONS. Attention, la peinture est encore fraîche et il doit encore rester quelques coquilles, mais ce cours en ligne, principalement destiné aux organisations et personnes qui fournissent déjà des services en ligne ou qui souhaitent en proposer à destination des associations, permet d’acquérir en autonomie une méthodologie et des techniques d’accompagnement qui vont bien au delà de la simple fourniture de services.

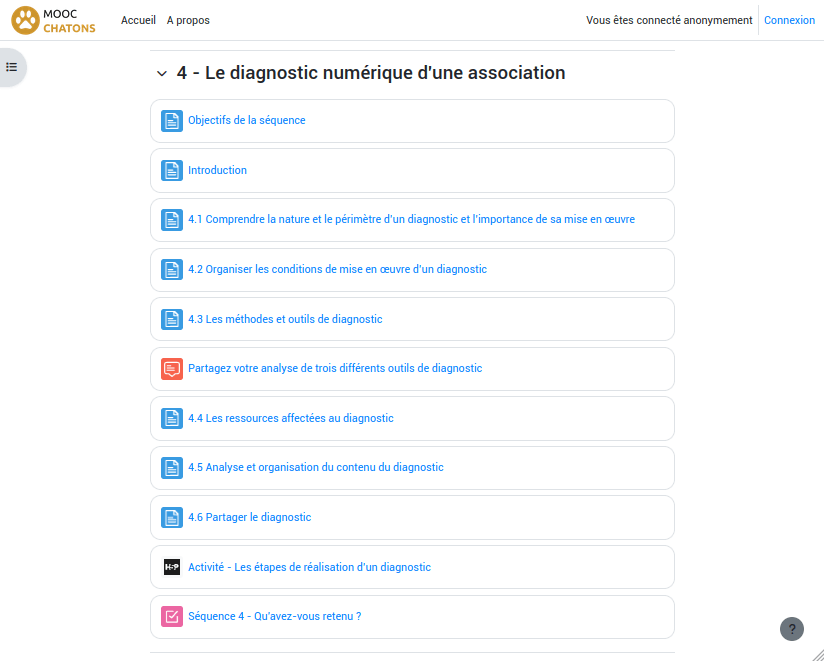
Reprenant dans les grandes lignes le séquençage pédagogique de la formation, le MOOC CHATONS #2 vous propose de naviguer à votre convenance au sein de 8 grandes thématiques, chacune d’entre elles proposant plusieurs leçons et un QCM (pour auto-évaluer les connaissances acquises). Chaque leçon s’articule autour de contenus textuels illustrés et propose parfois des activités à réaliser. Même si nous ne cherchons pas l’exhaustivité, nous avons essayé de synthétiser l’état des connaissances à disposition sur chaque sujet traité, et proposons systématiquement une rubrique « Pour aller plus loin » permettant à celles et ceux qui voudraient approfondir la question de consulter des ressources complémentaires.
Le cours est dorénavant ouvert, et chacun·e peut y participer quand bon lui semble : il n’y a pas de période d’inscription à respecter. D’ailleurs, il n’est même pas nécessaire de s’inscrire pour consulter les leçons. Nous vous conseillons cependant de créer un compte pour bénéficier de fonctionnalités avancées :
- accès aux exercices d’autoévaluation sous forme de QCM ;
- accès au forum d’entraide ;
- suivi de l’avancement de son parcours de formation (pour reprendre une leçon là où on s’est arrêté ou pour suivre les résultats aux évaluations).
Le maître-mot, ici, c’est l’autonomie. Nous voulons laisser aux apprenant·es un maximum de libertés dans leur parcours pédagogique : chacun⋅e peut suivre les leçons à son rythme et gérer son temps consacré à ce MOOC.
Comme d’habitude avec Framasoft, tous les contenus créés pour ce MOOC sont placés sous licence libre CC-By-SA (certaines images et vidéos issues de sites tiers sont signalées comme telles). Car nous espérons bien qu’il va évoluer, notamment grâce aux contributions et retours sur le forum d’entraide. Il faut donc voir ce MOOC comme un commun, organique, vivant : il grandit si l’on en prend soin. S’il manque des ressources, si une activité est à côté de la plaque, si une leçon est trop longue, nous vous invitons à partager votre avis sur le forum d’entraide et à proposer des améliorations.
Un site web pour faciliter la mise en relation des associations avec des prestataires, mais pas que…
Si permettre à des fournisseurs de services en ligne éthiques de monter en compétences en matière d’accompagnement des associations était le premier objectif du projet Emancip’Asso, le second était de créer un espace en ligne où les associations pourraient les identifier. C’est pourquoi dès l’origine du projet, nous avons prévu la création d’un site web permettant cette mise en relation. Mais avant de nous lancer dans la création du site, il nous fallait d’abord nous lancer dans la réalisation d’une identité graphique pour Emancip’Asso.
Une identité graphique et un design 👌
En septembre 2022, nous avons candidaté pour bénéficier de l’intervention d’un groupe d’étudiant⋅es sur la réalisation de la charte graphique et de l’identité visuelle du projet Emancip’Asso dans le cadre des projets tuteurés au sein de la licence pro Colibre. Après une première phase de présentation du projet et d’explicitation de notre commande, 4 étudiant⋅es ont réalisé un comparatif de chartes graphiques / identités visuelles de projets « voisins » avant de rédiger un cahier des charges présentant leur analyse du besoin, à partir duquel iels ont chacun⋅e élaboré une proposition de charte graphique. L’une de ces propositions correspondait à nos attentes et a servi d’inspiration à notre prestataire, Thomas Nicolas (merci à lui), pour la réalisation du logo.
![]()
En parallèle, nous avons postulé à un appel à projet de l’association Latitudes qui propose chaque année d’accompagner les organisations ayant un projet numérique engagé à le concrétiser via un dispositif de tutorat avec des élèves de leurs écoles partenaires. Entre octobre 2022 et janvier 2023, 3 étudiant⋅es de 2ème année de l’école d’ingénieurs CentraleSupélec ont travaillé à la réalisation d’un prototype pour le futur site web. Après un temps de découverte du projet, iels ont réfléchi à l’arborescence du futur site web et aux fonctionnalités à proposer sur chaque page avant de réaliser des maquettes via l’outil Penpot. Ces mock-up ont ensuite servi de base à notre prestataire, la Coopérative des Internets, pour créer le site web.
L’identité graphique et le design du site emancipasso.org résulte donc du travail de nombreuses personnes et nous sommes sacrément fier⋅es du résultat.

Un répertoire de prestataires, une communauté et des ressources
Le site emancipasso.org réalisé par La Coopérative des Internets (merci à elleux !) s’articule autour de 3 rubriques.
La première consiste en un répertoire de prestataires en mesure d’accompagner les associations souhaitant se lancer dans une démarche de transition vers des outils numériques libres.
On entend ici par « accompagnement », le fait d’accompagner l’association dans l’ensemble des étapes nécessaires à sa transition (co-élaboration d’une stratégie numérique, d’un diagnostic et de préconisations, mise en œuvre de celles-ci et accompagnement à la prise en main des solutions déployées). Nous avons en effet constaté que les associations peinaient souvent à trouver des professionnel⋅les réalisant ce type d’accompagnements sur mesure. Comme beaucoup d’organisations, les associations pensent d’abord « outils » avant de réfléchir à une stratégie numérique permettant que leur transition se déroule dans de bonnes conditions (sans retour aux services des géants du web au bout de quelques mois faute d’avoir pensé tous les aspects de cette transition). C’est pour cette raison que les associations ne trouveront pas dans ce répertoire des prestataires ne réalisant que le déploiement de solutions techniques. Nous avons d’ailleurs systématiquement demandé aux prestataires s’étant montré volontaires pour intégrer ce répertoire de nous fournir la preuve qu’ils avaient déjà mené plusieurs projets d’accompagnements auprès d’associations.

A ce jour, 20 prestataires sont recensés dans ce répertoire. C’est un début. Cela fait un petit mois que nous communiquons de manière active auprès des professionnel⋅les de l’accompagnement sur l’existence de ce site. De plus, nous comptons sur le fait que des hébergeurs de services ayant suivi la formation ou le MOOC se lancent à leur tour d’ici quelques mois. C’est donc encore actuellement un répertoire en devenir auquel vous avez accès. Si d’ailleurs vous connaissez des personnes ou organisations susceptibles d’y être référencées, n’hésitez pas à leur transmettre l’information.
Le site emancipasso.org est aussi pensé comme entrée pour rejoindre une communauté où les associations et les acteurices de l’écosystème du numérique émancipateur s’entraident, se conseillent, échangent des bonnes pratiques et font connaître leurs besoins en matière d’outils et/ou de fonctionnalités afin de mutualiser entre plusieurs organisations des coûts de développement. Partant du constat que les associations, et particulièrement les personnes en charge des aspects numériques au sein de celles-ci, n’ont à ce jour que très peu d’espaces pour échanger sur leurs pratiques en matière de transition numérique (merci d’ailleurs au Mouvement Associatif et ses délégations régionales qui s’emparent régulièrement de cette question), il nous a semblé essentiel de proposer un espace pour qu’elles se sentent moins isolées sur ces questions.
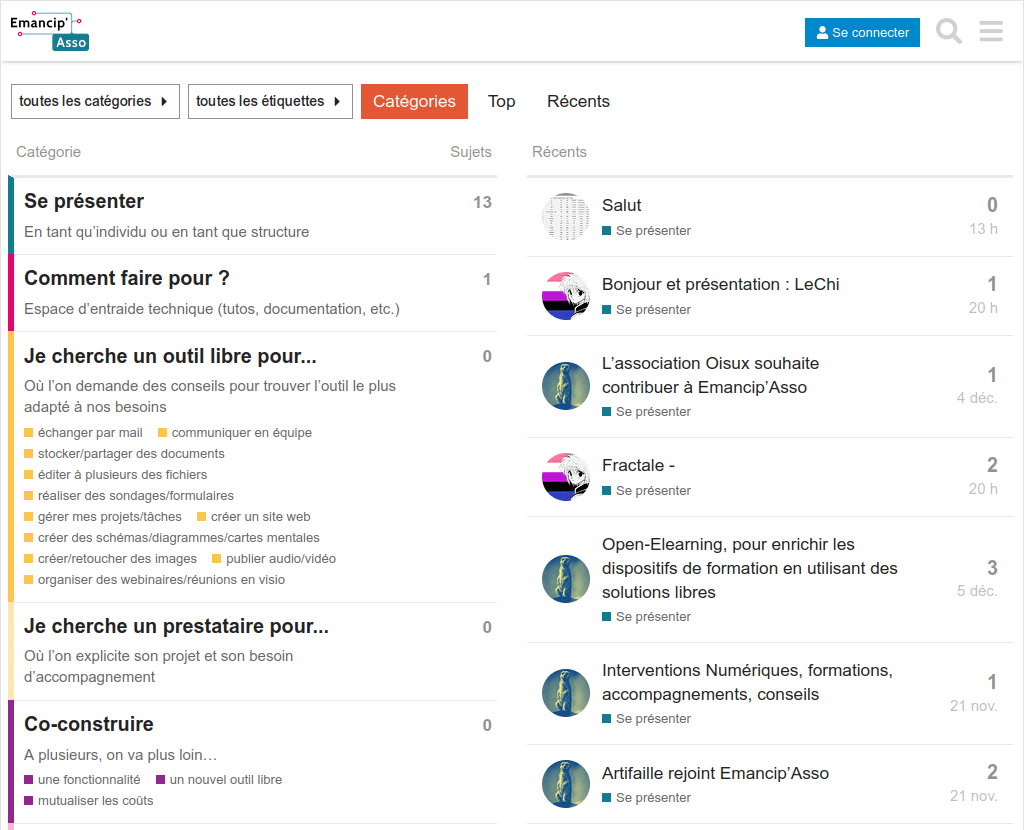
Enfin, la rubrique Ressources propose une sélection de contenus à destination des associations afin qu’elles puissent s’acculturer en autonomie à cette thématique du numérique éthique mais aussi à destination des prestataires afin qu’iels puissent perfectionner leur connaissance du monde associatif et leurs méthodes d’accompagnement. Notre objectif est de recenser ici un maximum de contenus pédagogiques pour favoriser l’émancipation du monde associatif. Si vous avez en stock des ressources que nous n’avons pas identifiées, n’hésitez pas à nous les faire connaître (en nous envoyant un petit mot sur contact (chez)emancipasso(point)org) afin qu’on les ajoute.
Et en 2024 ?
Dans les semaines et mois à venir, nous allons continuer à passer du temps sur le MOOC « Développer une offre de services pour accompagner les associations dans leur transition numérique éthique » afin de corriger ce qui doit encore l’être, améliorer certains contenus et ajouter des séquences vidéos issues de la captation qui a eu lieu pendant la session de formation.
Nous allons aussi continuer à solliciter des prestataires susceptibles de rejoindre le répertoire Emancip’Asso et traiter les candidatures. C’est un travail au long cours d’identifier toutes les structures existantes et de s’assurer qu’elles proposent réellement des offres à destination des associations intégrant une dimension d’accompagnement. Tout au long de l’année, nous essaierons d’être présent⋅es lors des principaux rassemblements des professionnel⋅les du numérique éthique et responsable afin de leur faire connaître ce dispositif et les inciter à le rejoindre.

Mais le plus gros du travail va être de réaliser la quatrième étape du projet : faire prendre conscience aux associations de l’incohérence qu’il y a à vouloir changer le monde en utilisant les outils du capitalisme et les inciter à se rendre sur le site emancipasso.org pour trouver ressources, entraide entre pairs et prestataires pour les accompagner dans leur transition. Pour cela, nous prévoyons de lancer une campagne de communication ciblée durant tout le mois de mars 2024. Nous y travaillons actuellement et espérons que vous nous aiderez à relayer nos supports de communication auprès de vos associations préférées ! Et toute l’année, nous présenterons le projet lors des principaux événements fédérateurs du monde associatif (Forum national de l’ESS, Universités d’été du Mouvement Associatif, Forum national des associations, etc.) afin de le faire connaître.
Enfin, à partir du moment où les associations auront connaissance du projet et qu’elles auront rejoins la communauté Emancip’Asso, nous mettrons davantage d’énergie sur l’animation de cette communauté afin de faciliter au mieux les échanges entre les participant⋅es. Notre objectif est que la communauté Emancip’Asso devienne un espace incontournable pour toutes les associations en cours de transition ou ayant réalisé leur transition numérique et que fréquenter cette communauté s’inscrive de manière permanente dans les pratiques associatives.
Merci de soutenir Emancip’Asso et Framasoft
Si jusqu’à maintenant les coûts liés au projet Emancip’Asso ont été pris en charge par la Fondation Charles Léopold Mayer pour le progrès de l’Homme (FPH), la Fondation Crédit Coopératif et la Fondation Un monde par tous, nous n’avons plus de sources de financement externe pour la suite du projet.
Donc si ce projet vous plaît, et que c’est possible pour vous, nous vous encourageons à soutenir Framasoft. Une partie de vos dons nous aideront à financer les coûts (campagne de communication et coordination du projet) du projet Emancip’Asso en 2024.
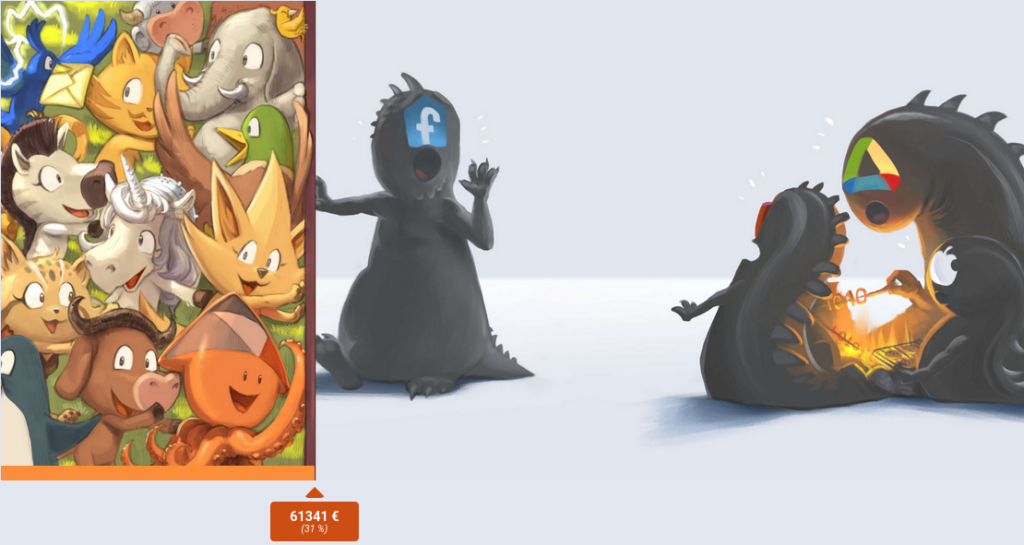
Cette année encore, nous avons besoin de vous, de votre soutien, de vos partages, pour nous aider à reprendre du terrain sur le web toxique des GAFAM, et multiplier les espaces de numérique éthique.
Nous avons donc demandé à David Revoy de nous aider à montrer cela sur notre site « Soutenir Framasoft », qu’on vous invite à visiter (parce que c’est beau) et surtout à partager le plus largement possible :

Si nous voulons boucler notre budget pour 2024, il nous reste tout juste 12 jours pour récolter 109 000 € : nous n’y arriverons pas sans votre aide !
Retrouvez les liens majeurs de cet article :
- le site de la formation de janvier dernier
- le cours en ligne « Développer une offre de services pour accompagner les associations dans leur transition numérique éthique »
- le site Emancip’Asso
- le bilan 2022 du projet




























{kind=link}