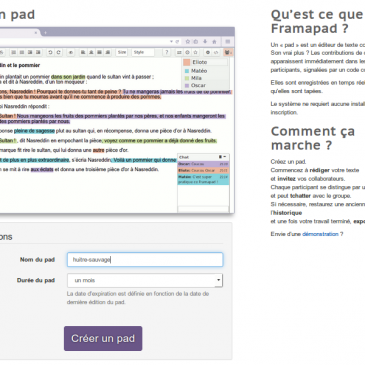
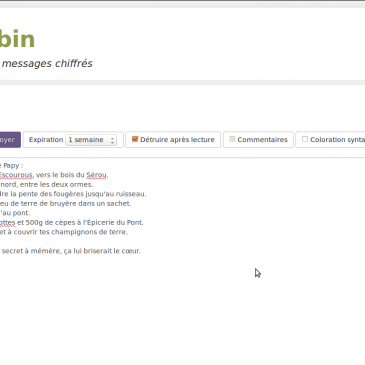
MyPads point de la semaine 17
Comme annoncé la semaine dernière, c’est désormais un point hebdomadaire qui émaillera le travail autour de MyPads. Cette semaine n’aura pas été de tout repos et les avancées visibles sont malheureusement peu nombreuses. Explications.