Un cas de dopage : Gégé sous l’emprise du Dr Valvin
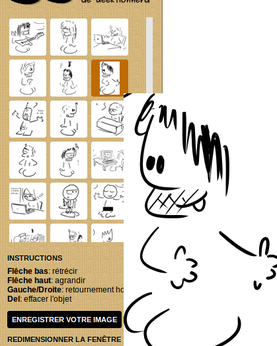
Quand un libriste s’amuse à reprendre et développer spectaculairement un petit Framaprojet, ça mérite bien une interview ! Voici Valvin, qui a dopé notre, – non, votre Geektionnerd Generator aux stéroïdes !