Sarah qui ? Ça raccroche !
Marre des appels indésirables ? Un développeur français vous propose de bloquer plus de 16 millions de numéros sur iOS et Android.

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code

Marre des appels indésirables ? Un développeur français vous propose de bloquer plus de 16 millions de numéros sur iOS et Android.
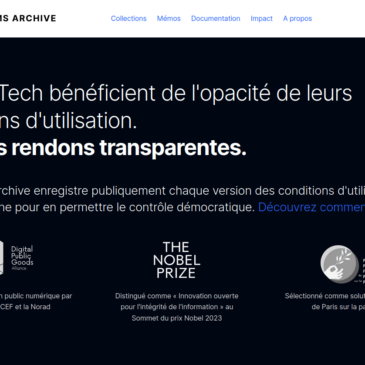
Les CGU (« Conditions Générales d’Utilisation »), c’est long, c’est en langage juridique… Bref, c’est chiant ! Du coup, quasiment personne ne les lit. Et c’est problématique. Car il s’agit du contrat qui vous lie à la plateforme.

Pour Framaspace, Framasoft a fait développer un outil de supervision de sites web nommé Argos Panoptès (ou juste Argos pour aller plus vite). Développé par Alexis Métaireau, développeur entre autres du générateur de site statique Pelican, et de l’outil de … Lire la suite

Le podcast est un média particulièrement consommé en France, comme le rappelait l’interview de Benjamin Bellamy de Castopod en mai 2022 sur ce même blog (aussi disponible en… podcast !). Il permet d’écouter une interview en faisant la vaisselle, des crêpes, … Lire la suite

Nous avons profité de la sortie d’une nouvelle version de l’application mobile pour interroger l’équipe de Piwigo, et plus particulièrement Pierrick, le créateur de ce logiciel libre qui a fêté ses vingt ans et qui est, c’est incroyable, rentable.

Le 12 janvier dernier, PVH éditions a annoncé la libération de sa collection Ludomire. Vu la faible fréquence de ce genre de démarche dans le milieu de l’édition traditionnelle, nous avons eu envie d’aller interroger ce courageux éditeur suisse.

Cet article a été publié à l’origine par THE MARKUP, il a été traduit et republié selon les termes de la licence Creative Commons Attribution-NonCommercial-NoDerivatives Démystifier le buzz autour de l’IA Un entretien avec Arvind Narayanan par JULIA ANGWIN Si … Lire la suite
Et si Framasoft se penchait un peu sur la solution collaborative libre Nextcloud ?