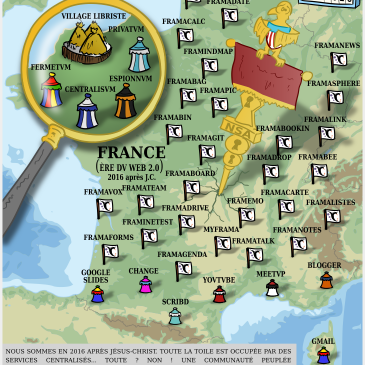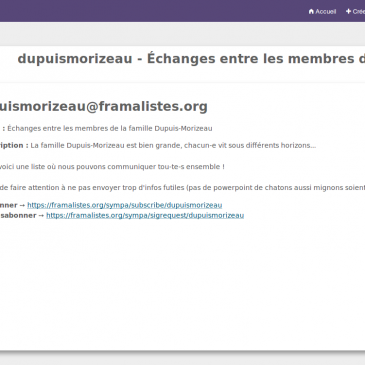
Framalistes : vos « Groups » n’ont plus à appartenir à Google
Entre nous, on peut se l’avouer : on revient toujours aux bons vieux emails groupés, hein ? Certes, Framateam nous permet de nous passer des groupes Facebook… Oui, Framavox est un outil extraordinaire pour discuter et prendre des décisions en groupe…